
LinkedIn come un database: tutorial per scovare fonti (e come non farsi denunciare per gli Epstein Files)
Sfrutta Google per 'hackerare' la ricerca di LinkedIn e scovare esperte/i. In più: come analizzare i 3 milioni di documenti del caso Epstein senza rischi legali (con il parere dell'avvocato).

Hola,
Sono Barbara D’Amico, giornalista e fu Google News Lab Teaching Fellow. Questa è la mia newsletter sul digital journalism, un modo per restare in contatto con me, sapere cosa combino e ricevere news su corsi, eventi e punti di vista fondamentalissimi su quanto accade nell’infosfera online.

Cosa c’è in questo numero:
Come sfruttare LinkedIN per scovare fonti e profili (con 3 livelli di esempio suddivisi in A, B e C)
Risorse ragionate per consultare gli Epstein Files in modo corretto e un parere dell’avvocato esperto in protezione dei dati.
Se non vi interessa il tutorial passate al capitolo 2.
Quanto al parere legale, ringrazio l’Avv. Prof. Massimiliano Càrpino, Professore a contratto di diritto alla protezione dei dati personali - Università Cattolica del Sacro Cuore di Milano. Trovate il suo intervento alla fine del capitolo 2 utile a evitare una denuncia per detenzione di materiale pedoporfornografico.
Prima di iniziare, la solita avvertenza: questo numero è luuuungooooo quindi potreste vederlo troncato in email: rimediate aprendolo in una finestra separata o leggendolo direttamente su Substack).
Corsi
📌 C’è una nuova edizione del Corso Odg per giornaliste/i (con crediti formativi) dal titolo Fact-Checking e Media Literacy: buone pratiche e strumenti per creare lettori consapevoli.
Come nell’edizione di Torino faremo sia teoria che pratica di verifica online. Sarà in presenza, a Cuneo, nella sede di Confindustria (via Bersezio 9) - il 6 marzo. So che i posti si riempiono rapidamente ma cercatelo e iscrivetevi qui www.formazionegiornalisti.it/
📌 Stiamo per rilanciare con il team di Fior di Risorse anche le nuove sessioni del corso AI al lavoro
È un corso base teorico-pratico per chi vuole un’infarinatura concreta sull’uso delle AI per il proprio lavoro in azienda o come freelancer, imparandone le basi e gli impieghi consapevoli: ne uscite sapendo fare cose. Monitorate quindi i miei post e la mia newsletter nei prossimi giorni (e seguite il presidente di Fior di Risorse, Osvaldo Danzi) per poter conoscere contenuti, tempi, costi e iscrivervi. Qui, intanto, qualche feedback sulla prima edizione.
📌 Consulenze in arrivo!
Dato che in molte e molti me le chiedete, ho deciso di aprire delle sessioni di formazioni/consulenze one-to-one (quindi non in gruppo) con me, faccia a faccia online, personalizzabili, accessibili e molto concrete per supportarvi in attività redazionali e non solo.
Quel dataset che non riuscite a trovare, quella verifica che non avete tempo di fare direttamente, o semplicemente un confronto su un progetto editoriale, e così via. L’approccio sarà, come sempre, molto concreto. Seguite la newsletter per avere presto info su calendario, modalità e costi.
Bene, iniziamo!
1. Come usare LinkedIN per scovare fonti
La scorsa settimana ho pubblicato un’edizione con un tutorial che sembra - leggendo i commenti - piacere molto: serve a creare una rassegna stampa automatica con tool gratuiti e pochi passaggi (qui se vuoi recuperarlo).
Sulla scia di questo entusiasmo, ho creato un nuovo tutorial su come usare i cari vecchi operatori di ricerca per rintracciare profili di esperte/i su LinkedIN.
Ingredienti:
Google Search, senza la modalità AI MODE attiva, useremo la classica barra di ricerca (do you remember barra di ricerca, sì? Questa qui):

Un account LinkedIN, il motore di incontro domanda/offerta di lavoro più famoso al mondo, motivo per cui lo useremo come database (l’account vi serve solo per poter poi contattare i profili);
Un foglio word/google doc/appunti, insomma un pezzo di carta virtuale dove segnare le formule con gli operatori di ricerca (ovvero simboli del tipo intext: o l’uso delle virgolette per cercare una parola specifica, che combinati insieme permettono di raffinare uno scavo online).
Se non sapete cosa sono questi operatori, ecco qui un ripasso sempre valido.
Potreste chiedervi e chiedermi: “Ma perché usare formule, operatori, Google Search che è ormai preistorico, se posso semplicemente chiedere alle AI di fare uno scavo per me o andare su LinkedIN e cercare lì i profili?”.
E sareste persone intelligenti a farlo.
La risposta è questa: LinkedIN, come qualunque altra piattaforma social, è disegnata per trattenere gli utenti al suo interno, offrendo strumenti di ricerca del proprio sconfinato database di profili.
Questi strumenti, però, sono volutamente programmati per limitare lo scavo gratuito e favorire quello a pagamento - giustamente - attraverso servizi extra (per esempio per il recruiting, o per vedere chi ha visitato il nostro profilo nell’ultima settimana).
Le AI non possono fare scavi approfonditi su piattaforme che richiedono accesso tramite account/login, motivo per cui spesso vi reindirizzano a profili non esatti o non accessibili (o vi rispondono “mi spiace ma non posso accedere a…”).
Infine, LinkedIN serve per offrire/cercare lavoro (in teoria) quindi è pieno zeppo di annunci e post che inquinano la ricerca (provate a cercare “marketing specialist” così, e tirerete su una marea di job post, sicuramente anche molti profili ma sempre nella gabbia di ricerca limitata di LinkedIN).
Per tutti questi motivi, signori e signore della giuria, siamo qui oggi per testare delle strade differenti.
Queste tecniche banali che invece vi spiego oggi garantiscono che abbiate il controllo sullo scavo e soprattutto vi permettono di personalizzare la ricerca in base alle vostre reali esigenze.
A. Esempio (scavo generale)
Stai scrivendo un comunicato stampa su un argomento - mettiamo che sia “food” - e vorresti inviarlo solo a giornaliste/i italiani attivi che si occupano di quel tema, ma non vuoi usare banche dati a pagamento:
Apri Google Search
Nella barra di ricerca incolla questa formula (così com’è, non cambiare le spaziature)
site:it.linkedin.com -inurl:jobs "GIORNALISTA" and "Food"Puoi anche omettere AND in realtà, ormai la ricerca congiunta è di default.
Scorri i risultati che vedi nella pagina di ricerca Google poi clicca sul profilo che ti interessa. Attenzione: ovviamente questo metodo non vi permette di tirar giù in blocco un elenco di contatti, ma è già molto più utile perché vi dà la visione di insieme;
Fact-Checking » LinkedIN è un cv a cielo aperto, completamente auto-dichiarativo, quindi chiunque può dire di sé qualunque cosa ma non è detto che sia vero (lauree, titoli, esperienze ecc…). Prima di dar per scontato che le informazioni che leggi siano corrette, contatta direttamente le persone oppure leggi almeno le “raccomandazioni”, cioè i feedback lasciati da persone che hanno lavorato con quella persona.
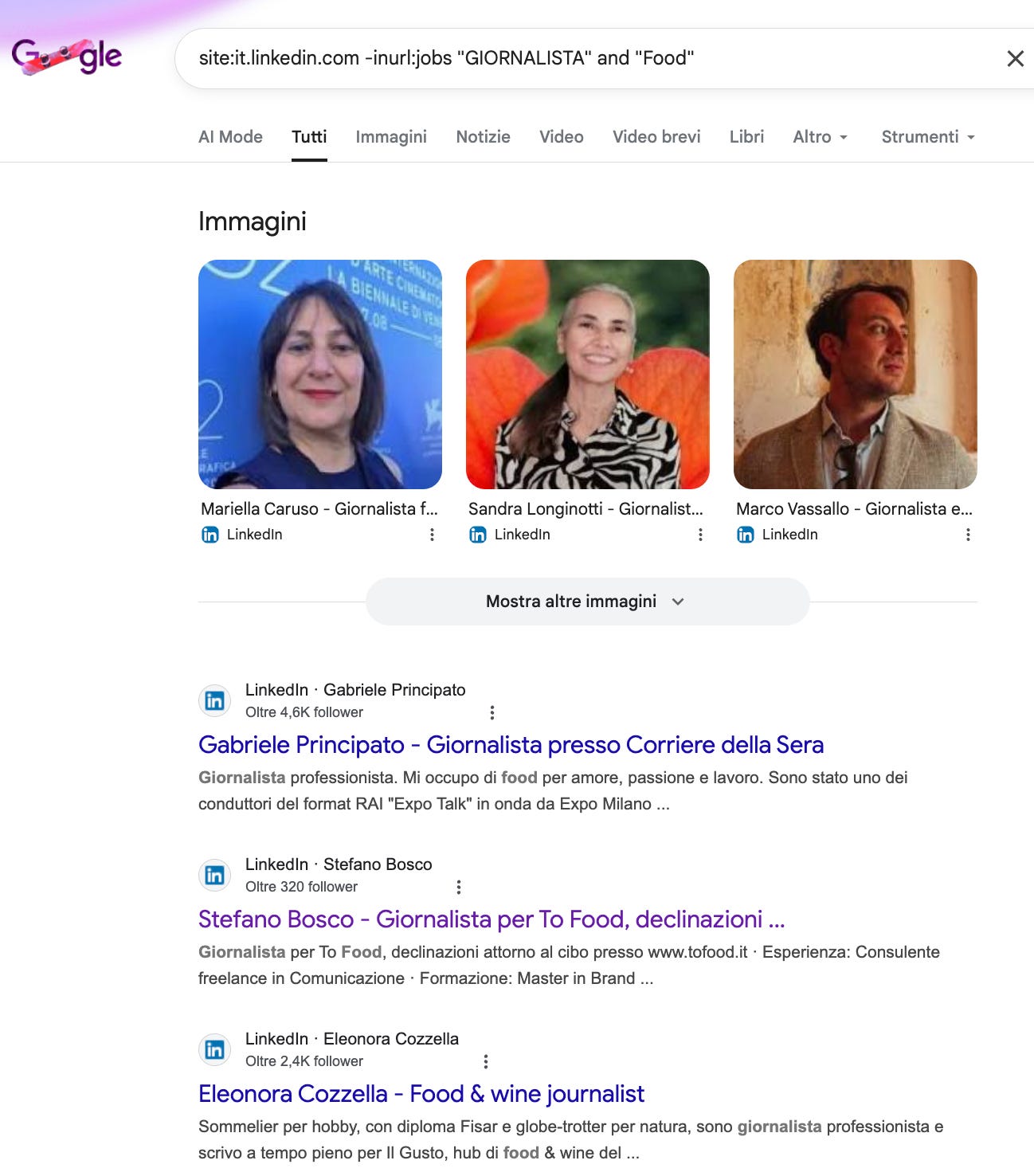
Un profilo poco attivo, con poche informazioni e senza referenze non è una grande garanzia.
Spiegone: cosa significano queste formule
ATTENZIONE » Prima di incollare la formula, ti guido nella sintassi per capire che cosa stai chiedendo a Google:
“site:” è un operatore che chiede a Google di concentrare la ricerca solo dentro un determinato sito (infatti, dopo i due punti vedrete che ho inserito il dominio italiano di LinkedIN proprio perché a me interessano giornalisti italiani e presumo che abbiano fatto l’iscrizione su LinkedIN in italiano).
“inurl:” è un altro operatore che chiede a Google di concentrare la ricerca delle keyword direttamente nell’url, quindi proprio nell’indirizzo web con cui una pagina di profilo Linkedin è salvata (anche se non possiamo vederlo sempre in chiaro).
Anche se non ci pensiamo, i siti di queste piattaforme sono appunto siti web molto articolati e si comportano come tali: hanno pagine, sotto-pagine, directory ecc… Tutto ciò è tracciabile con indirizzi e url che contengono spesso parole chiavi ricorrenti. Le stesse che possiamo sfruttare per includere o escludere certi risultati dalla nostra ricerca.
Dato che gli annunci di lavoro per “giornalista” o settore “food” generano una url che contiene “jobs” e io non voglio pescare questi annunci, ma solo i profili dei giornalisti e delle giornaliste che si occupano di food, allora metto il segno meno davanti a inurl seguito dalla parola chiave che voglio escludere dalla ricerca, ovvero “jobs”.
-inurl:jobs
C’è però un problema: questo scavo, seppur buono, mi fornisce dei risultati un po’ sporchi e che includono tutto ciò che non è un annuncio di lavoro.
Rischi: oltre ai profili delle persone, potresti quindi trovare:
Pagine aziendali (Company Pages).
Post o articoli pubblicati su LinkedIn (Pulse).
Gruppi o pagine di enti ecc…
Elenchi di iscritti raggruppati per città o settore.
Magari ti interessano, magari no. Vediamo allora come affinare la ricerca.
B. Esempio (scavo chirurgico)
Sei sempre con il comunicato in mano, ma dopo aver visto i risultati non hai trovato ciò che ti serve. Fai così:
Apri Google Search
Nella barra di ricerca incolla questa formula (così com’è, non cambiare le spaziature, di nuovo)
site:it.linkedin.com (inurl:in OR inurl:pub) -intitle:directory -inurl:dir -inurl:jobs "GIORNALISTA" and "Food"Questa formula è molto più avanzata perché utilizza dei filtri di esclusione e inclusione specifici per i profili utente:
(inurl:in OR inurl:pub) » I profili personali di LinkedIn hanno quasi sempre
/in/o/pub/nell’URL. Forzando questa condizione, dici a Google di mostrarti solo persone, non aziende.-intitle:directory e -inurl:dir » Questi comandi eliminano le “pagine elenco” (directory) di LinkedIn, che spesso appaiono nei risultati di Google ma sono poco utili se cerchi un singolo contatto.
Risultato: Otterrai una lista molto più pulita di singoli professionisti - direttamente nei risultati di ricerca Google Search - che si definiscono giornalisti nel settore food.
Fact-Checking » valgono poi le stesse premesse: lo dicono loro che sono giornalisti del settore food, quindi per citare Paolo Fox, non crederci ma verificalo.
Es. Cerca site:www.testatagiornalistica.it nome e cognome giornalista tema
site:repubblica.it “pinco pallo” “ricetta”
C. Esempio (scavo chirurgico con luogo e categoria)
Infine, se volessi concentrare la tua ricerca solo su profili che lavorano in un determinato luogo o area geografica oppure volessi escludere l’appartenenza a certe categorie - es. non giornaliste/i freelance - allora usa queste formule:
Aggiungi il segno -paroladaescludere in questo modo:
site:it.linkedin.com (inurl:in OR inurl:pub) -intitle:directory -inurl:dir -inurl:jobs "GIORNALISTA" "Food" -freelance -libero -collaboratore -collaboratriceModifica la formula se vuoi circoscrivere il luogo aggiunendo la città o l’area come se fosse una normale parola chiave o di ricerca tra virgolette:
site:it.linkedin.com (inurl:in OR inurl:pub) -intitle:directory -inurl:dir -inurl:jobs "GIORNALISTA" "Food" "Roma"Ovviamente puoi combinare più criteri usando una sola formula, scegliendo di fare lo scavo direttamente su www.linkedin.com e in qualunque lingua tu voglia se vuoi allargare la ricerca.
Ogni tanto Google potrebbe chiederti se sei un robot, assicuralo che sei umana/o e procedi.
Come usare gli operatori per cercare offerte di lavoro
TIPS » Se invece volessi usare queste tecniche per cercare annunci di lavoro senza entrare su LinkedIN basterà togliere il segno meno da -inurl:jobs
3. Apri sempre Google Search e incolla questa formula
site:it.linkedin.com (inurl:in OR inurl:pub) inurl:marketing specialist inurl:jobsDovrai usare 2 inurl in particolare:
quello con il profilo di lavoro ricercato (nell’esempio ho cercato offerte come “marketing specialist” inurl:marketing specialist ma puoi mettere quello che preferisci es. ingegnere);
quello per concentrare la ricerca sugli annunci, quindi inurl:jobs
Come ottenere risultati più recenti nel tempo
Come si faceva una volta, ovvero:
Ottenuta la ricerca su Google Search, clicca in alto sul menù STRUMENTI e seleziona QUALSIASI DATA e da lì seleziona il periodo entro cui vuoi restringere la ricerca
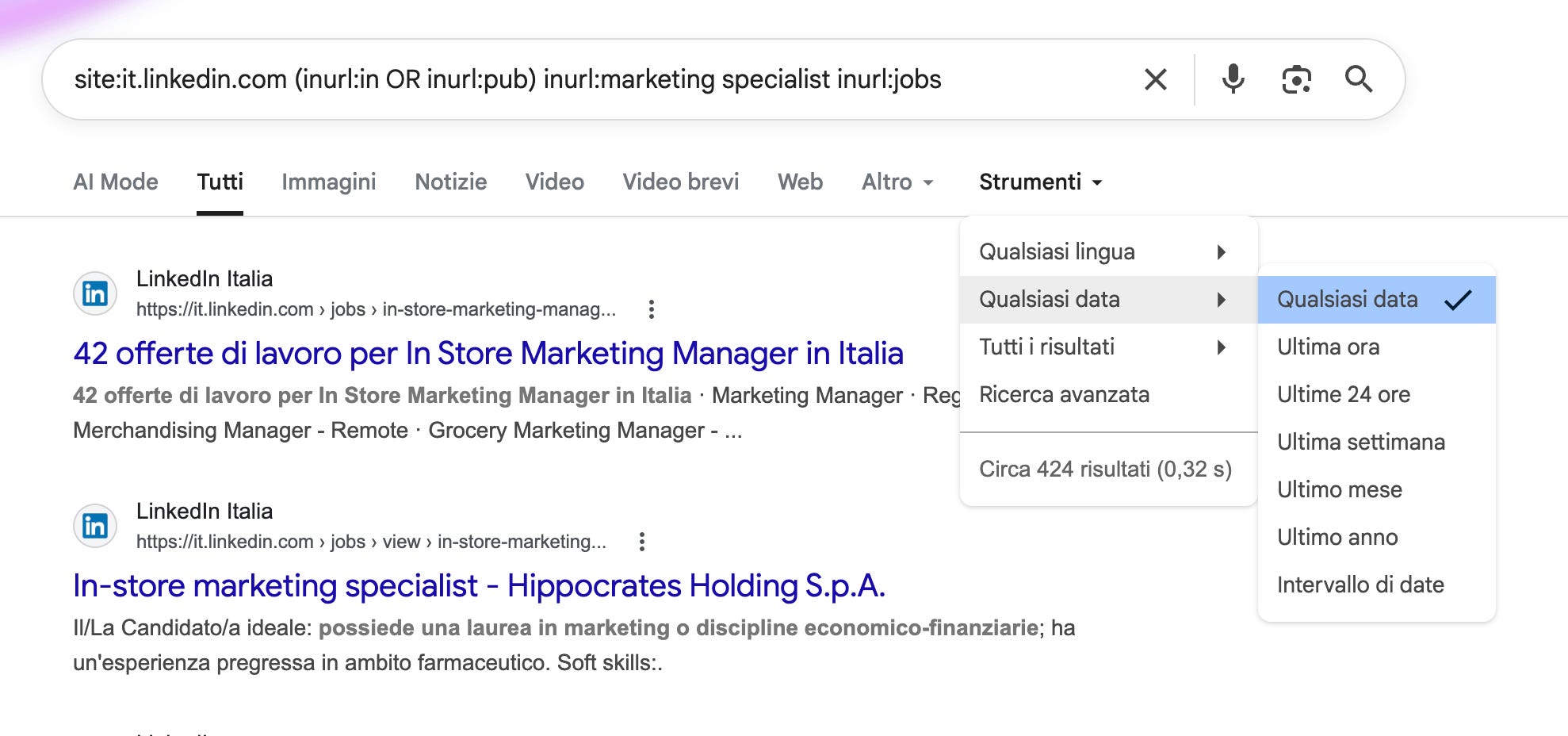
Questo farà emergere i profili o gli annunci che risultano essere stati aggiornati nel lasso di tempo indicato (es. nell’ultima ora, nelle ultime 24 ore, settimana, mese, anno ecc..).
Ora, immagina di poter sostituire il nome del settore “food” con qualunque altro occorra per il tuo scavo: magari ti serve un parere di medico chirurgo esperto in trapianti, di un rappresentante sindacale locale ecc… le combinazioni sono infinite.
2. Risorse per analizzare gli Epstein Files
La storia la sapete: il Dipartimento di Giustizia degli Stati Uniti (Department of Justice o DoJ) ha pubblicato da qualche settimana oltre 3 milioni dei 6 milioni di documenti che hanno come minimo comune denominatore il miliardario e pedofilo Jeffrey Epstein (morto nel 2019). Si chiama, appunto, Epstein repository.
Si tratta di intercettazioni e, per lo più, report di polizia, FBI ecc…, con una quantità di materiale multimediale abnorme sui rapporti tra Epstein e personaggi in vista e soprattutto sui suoi party a base di minori, abusi ecc…
Motivo per cui il materiale dei file è disturbante - molti contenuti sono pedopornografici o riguardano descrizioni di crimini violenti - e per il coinvolgimento di nomi grossi delle élite politiche, industriali e culturali di tutto il mondo.
Di fatto è una sorta di Wikileaks ma con un attore principale al centro. La differenza, rispetto a molti altri leaks emersi nella storia del giornalismo, è che oggi i mezzi tecnologici a basso costo consentono a chiunque di scavare e analizzare meglio i materiali e le connessioni.
Ecco qui il problema: chiunque.
Se in queste settimane avete avuto la nausea nell’imbattervi in tweet/post con stralci e screenshot di email con dati in chiaro, video non più sfocati (perché nel DoJ i materiali sono spesso “redacted”, cioè oscurati) ecc… non siete sole/i.
⚙️ Credo sia importante mappare gli strumenti utili perché questo scavo possa essere fatto con un minimo di orientamento, velocità (anche se ci vorranno mesi per verificare connessioni/piste e incrociare i dati) e soprattutto con qualche accorgimento che mi sembra per ora assolutamente ignorato: la tutela della privacy e la consapevolezza che comunque quello che si sta maneggiando è materiale informativo tutt’altro che innocuo perché coinvolge moltissime persone minorenni all’epoca dei fatti.
🛑 Attenzione quindi a pubblicare con leggerezza gli stralci degli Epstein Files: il fatto che siano desecretati - e appunto per molti aspetti non lo sono del tutto - non significa che chiunque possa pubblicare dati in chiaro, dati sensibili, soprattutto delle vittime e soprattutto di vittime all’epoca bambine e bambini (anche se oggi fossero maggiorenni).
Per questo:
Ho creato una mini-repository dei database che, oltre a quello ufficiale del DoJ, sono comparsi in questi giorni e con cui si possono analizzare gli Epstein Files in modo più semplice (questo documento è in aggiornamento);
Ho chiesto il parere di un legale esperto, Massimo Càrpino, avvocato e docente dell’Università Cattolica del Sacro Cuore di Milano, che ho avuto piacere di ascoltare come speaker durante una sessione formativa sull’uso di risorse per il giornalismo investigativo lo scorso settembre grazie all’Next-IJ Training Programme.
Cosa si rischia a maneggiare male gli Epstein Files
Il fatto che nella stragrande maggioranza dei casi le vittime menzionate siano straniere o legate a fatti anche molto lontani nel tempo, non permette di abdicare a un principio basico del giornalismo: la tutela di chi ha subito o si teme possa aver subito violenza.
A maggior ragione, nei casi in cui manca l’avvio di un processo legale - con fatti accertati - dovrebbero valere le stesse cautele che si usano quando si apprende di un reato (anche solo potenziale) e ne si racconta la storia: vietato sbattere online dettagli che faciliterebbero l’individuazione delle vittime.
Ma lo stesso principio vale per chi viene citato nelle mail o chiamate intercettate. Prima di pubblicare uno screenshot bisognerebbe verificare l’esistenza di nessi, riscostruire il contesto, per comprendere la ragione della menzione: esattamente come in statistica “correlation is not causation”, così la menzione da sola non è sufficiente a inquadrare un soggetto come autoreo o complice di un crimine.
Valgono poi le considerazioni classiche: è chiaro che se c’era un’indagine (o inchiesta giornalistica) ben prima che il leak emergesse, e troviamo nei documenti la conferma o le prove di quanto indagato, allora ne possiamo e dobbiamo parlare.
Prendete il caso del Principe Andrea, al centro dello scandalo, stra-citato nei documenti anche sotto pseudonimo e arrestato mentre scrivo questo numero (anche se non per le accuse che credete).
Il parere dell’avvocato:
Quindi, che cosa rischia a livello legale un giornalista italiano che maneggia incautamente gli Epstein Files* e che cosa rischia invece una persona non giornalista che fa la stessa cosa (in entrambi i casi, in particolare, con un focus sul materiale con vittime minori all’epoca dei fatti)? [I neretti nelle risposte di Càrpino li ho aggiunti io ]
*(es. facendo screenshot con dati sensibili in chiaro di email e intercettazioni non ancora oggetto di processi o verifiche giudiziarie o non ancora contestualizzati correttamente in una più ampia inchiesta giornalistica e pubblicando il tutto sui social?)
“In linea generale la pubblicazione di dati (a maggior ragione se prima riservati) da parte di chi ne è il legittimo detentore non legittima di default chiunque a trattarli per il solo fatto che hanno assunto lo status di dato pubblico. Il dato reso pubblico ossia diffuso ad una platea indeterminata di persone non legittima di per sé qualunque trattamento di quei dati”- mi spiega l’avvocato Massimiliano Càrpino.
“In primis deve essere stabilita la finalità dell’ulteriore trattamento (i.e. post pubblicazione) ossia l’obiettivo di una successiva pubblicazione di quei dati (integralmente ovvero con elaborazioni/arricchimenti/commenti di chi effettua l’ulteriore trattamento).
Una volta stabilità la finalità (che deve essere determinata, esplicita e legittima) prima della successiva ulteriore pubblicazione (più o meno arricchita/commentata) è necessario tenere in considerazione una serie di diritti e libertà fondamentali delle persone, tutti di rango costituzionale, che devono essere tenuti in debita considerazione.
In sostanza bisogna essere in grado di effettuare (e documentare di aver effettuato) un bilanciamento tra diritti di rango costituzionale che sono spesso confliggenti tra loro ma comunque tutti meritevoli di tutela. Nel nostro caso da una parte il diritto di cronaca/libertà di manifestazione del pensiero con il diritto alla dignità e integrità psico/fisica della persona, il rispetto della vita privata e familiare, il diritto alla protezione dei dati personali, il diritto alla non discriminazione, la presunzione di innocenza e il diritto di difesa.
Fatta questa doverosa premessa trovo molto rischioso, rispetto alla tutela di tutti i diritti confliggenti con quello di cronaca, la pubblicazione decontestualizzata e integrale di mere porzioni di atti processuali, immagini e video che contengono verosimilmente molteplici fatti-reato (anche molto gravi).
Maggiori cautele dovrebbero essere poste da coloro che non svolgono professionalmente l’attività giornalistica ma che pur avendo il diritto, come tutti i cittadini, di manifestare liberamente il loro pensiero, non hanno di norma le competenze, l’esperienza e gli oneri deontologici ed etici dei giornalisti.
Sul piano oggettivo il rischio è quello di fornire una rappresentazione distorta o comunque incompleta della verità e della continenza dei fatti narrati potendo così sconfinare nella mistificazione scandalistica e/o offensiva di fatti di per sé verosimilmente già molto gravi.
Un giornalista dovrebbe chiedersi in che modo soddisfare appieno e in maniera inappuntabile l’interesse pubblico a conoscere quella notizia, modalità che non può non essere figlia di quel bilanciamento di interessi contrapposti.
Dal punto di vista soggettivo tutte le persone fisiche identificate o identificabili che emergono dai file (vittime, imputati, persone informate sui fatti) hanno il diritto di difendersi nelle sedi a ciò deputate e, per quanto riguarda i soggetti minori all’epoca dei fatti, anche quello eventuale della non ostensione dei loro dati personali.
I rischi legali che si possono correre in assenza delle cautele necessarie spaziano come minimo dal trattamento illecito di dati personali alla diffamazione senza contare, per i giornalisti, gli aspetti etici e deontologici. Non si può nemmeno escludere a priori, qualora disponibili in versione integrale, il reato di detenzione e/o diffusione di materiale pedopornografico se immagini e video abbiano come soggetti minori di età.”
(Avv. Prof. Massimiliano Càrpino, Professore a contratto di diritto alla protezione dei dati personali nella Università Cattolica del Sacro Cuore di Milano)
Che cosa dice Bellingcat a riguardo?
Quindi, chiedere a Grok (l’AI di X/Twitter) di eliminare la sfocatura da foto e video, mette nei guai chi pubblica oltre a creare un danno alle vittime che possono rivalersi su chiunque diffonda i contenuti.
Così come scaricare in blocco l’intero dataset degli Epstein Files che contengono prove di reato di pedopornografia senza uno scopo chiaro e dichiarato di inchiesta (chi fa informazione potrebbe avere necessità di scandagliare il materiale, ma chiunque altro no).
Ricordo un caso a La Stampa molti anni fa in cui un giornalista, per provare che si poteva acquistare droga e farsela spedire a casa direttamente su certi canali online, fece arrivare un pacco di cocaina in redazione (ma si era prima auto-denunciato alle autorità e aveva avvertito la polizia).
Allo stesso modo giornaliste e giornalisti possono far valere il diritto di cronaca, ma è un limite troppo labile nel caso Epstein: prima di sbattere online stralci di conversazioni disturbanti, bisognerebbe almeno ricostruire e verificare il contenuto e valutare la necessità di pubblicazione in chiaro.
Pensate a questo: come mai Bellingcat, che è una delle redazioni di inchiesta tra le più importanti al mondo ed esperta di OSINT e leaks, è anche tra le poche realtà editoriali che non ha ancora creato un database o repository a parte per gli Epstein Files? (Almeno, non mentre scrivo).
Perché il rischio è di facilitare la ricerca di materiale pedopornografico e di mettere a rischio, di nuovo, l’identità e l’integrità delle vittime al tempo minorenni, di coloro in particolare che vogliono mantenere l’anominato ancora oggi anche se sono diventati maggiorenni (è un loro diritto).
Lo spiega bene la redazione in questo articolo che denuncia appunto come molti su X stiano usando l’AI di Grok per “sblurrare” cioè rendere chiaramente visibili volti e corpi che compaiono nei video e nelle foto rinvenibili negli Epstein Files.
Il problema non è consultare gli Epstein Files ma detenerne il contenuto e rilanciarlo.
Non conoscendo a priori cosa potrà contenere quel video o quella foto, rischiamo di rendere pubblici dati più che sensibili.
📌 Consulta il database delle risorse
Esistono però anche enormi sforzi per creare database che siano facilmente navigabili e permettano appunto di capire che cosa c’è dentro i file prima di scaricarli.
Ho creato allora una piccola raccolta su Google Fogli (che potrete aggiornare anche voi segnalandomi qui in email altre risorse in cui vi imbatterete) di questi sistemi organizzati.
Il criterio di selezione è il seguente:
Devono essere tool che pescano direttamente dal database ufficiale messo a disposizione del DoJ, non da fonti terze o rimaneggiate;
Non devono provenire da fonti dubbie (es. canali di propaganda o bot);
Il foglio Google è diviso in due sezioni:
Link con i database diretti (quindi entrate e cercate parole chiave per estrarre contenuti dagli Epstein Files, o incrociare correlazioni o altro);
Link ai sistemi scaricabili da GitHUB* (qui occorre però saper smanettare un po’ per installare lo strumento direttamente sul proprio desktop » come sempre leggete bene prima istruzioni).
Per esempio ho scoperto così che che Courier Newsroom ha creato una repository usando Pinpoint e quindi permette la navigazione in blocco dei documenti con una consultazione massiva e smart per parole chiave, enti, soggetti menzionati, luoghi ecc…
🔎 Clicca per vedere le risorse sugli Epstein Files qui » Database dei Documenti Jeffrey Epstein (creati sulla base della repository DoJ)
* Anche per le app di GitHUB ho usato criteri per scremare i tool disponibili, aiutandomi con la funzionalità Ragionamento di Gemini per la selezione, in particolare:
Verifica del Codice: ho privilegiato i repository con file
READMEdettagliati e codice trasparente (Python, JS, C#), che permettono di verificare come i dati vengono trattati.Neutralità Politica: ho escluso le repository che contenevano riferimenti a teorie del complotto non supportate o terminologia legata a bot-net. Le risorse di Courier Newsroom e dei ricercatori su GitHub sono focalizzate sulla trasparenza dei dati e sull’analisi forense dei documenti (poi, chiaramente, bisogna verificare che sia così);
Integrità DoJ: Tutti questi strumenti utilizzano come “seed” (punto di partenza) i dataset 1-12 rilasciati ufficialmente sul sito justice.gov/epstein.
Bene, penso sia “tanta roba” come dicono quelli bravi.
Io vi lascio digerire, fate buon uso di queste tecniche e ci leggiamo lunedì con il prossimo numero.